System Overview
This repository ships the open-fdd Python package on PyPI: YAML-defined FDD rules on pandas (open_fdd.engine), plus schema and reporting helpers. That engine can run inside your own application or inside the AFDD Docker stack (separate repo), which installs open-fdd from PyPI and adds TimescaleDB, scrapers, FastAPI, and a React UI.
The text below describes the full edge platform as deployed from open-fdd-afdd-stack—knowledge graph, services, and data flow. For engine-only usage, see Engine-only / IoT and Getting started.
Architecture
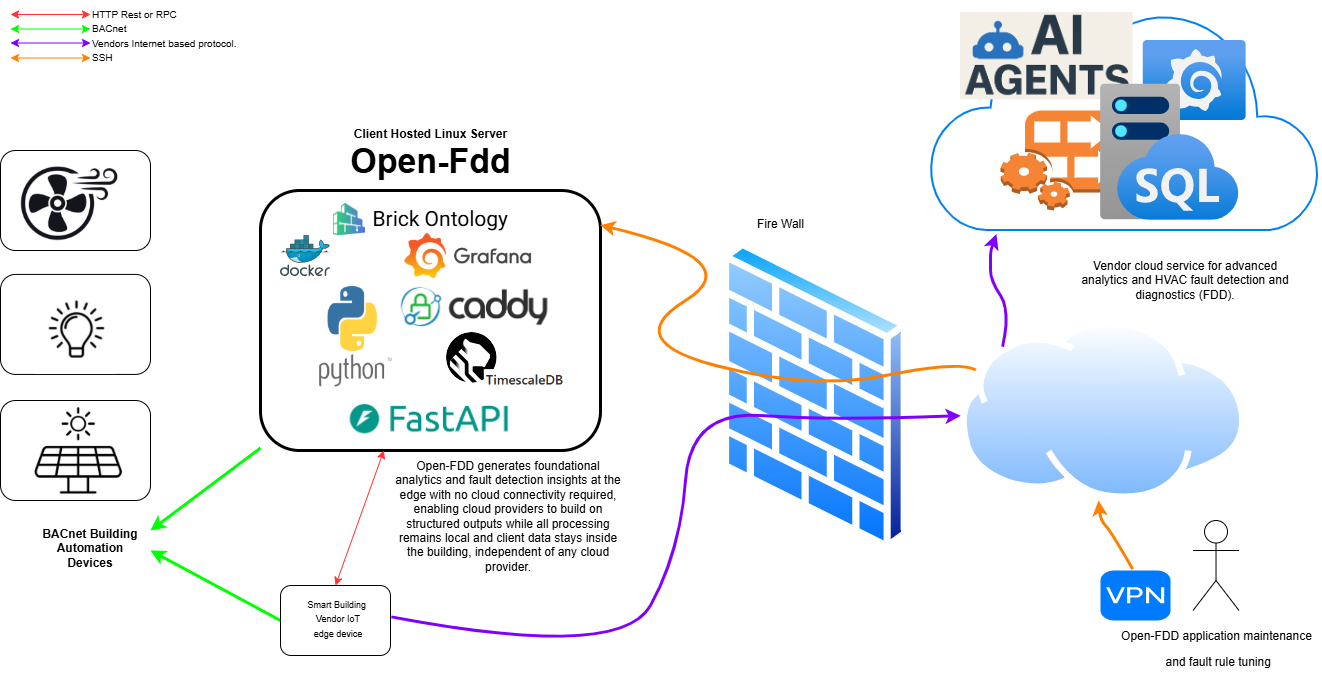
This project is an open-source stack; a cloud or MSI vendor can develop their own Docker container and deploy it on the same client-hosted server that runs Open-FDD, pulling from the local API over the LAN. That approach removes the need for a separate IoT or edge device dedicated to the vendor.
Services
| Service | Description |
|---|---|
| API | FastAPI CRUD for sites, equipment, points. Data-model export/import, TTL generation, SPARQL validation. Swagger at /docs. Config UI (HA-style data model tree, BACnet test) at /app/. |
| Grafana | Pre-provisioned TimescaleDB datasource only (uid: openfdd_timescale). No dashboards; build your own with SQL from the Grafana SQL cookbook. Use --reset-grafana to re-apply datasource provisioning. |
| TimescaleDB | PostgreSQL with TimescaleDB extension. Single source of truth for metadata and time-series. |
| BACnet scraper | Polls diy-bacnet-server via JSON-RPC. Writes readings to timeseries_readings. |
| Weather scraper | Fetches from Open-Meteo ERA5 (temp, RH, dewpoint, wind, solar/radiation, cloud cover). |
| FDD loop | Runs every N hours (see rule_interval_hours, lookback_days in platform config). Pulls last N days from DB into pandas, reloads all rules from YAML on every run (hot reload), runs rules, writes fault_results back to DB. No restart needed when tuning rule params. |
| diy-bacnet-server | BACnet/IP JSON-RPC bridge. Discovery and present-value reads via JSON-RPC; Open-FDD merges discovery into the data model (RDF/TTL), not a required CSV. |
Campus-based architecture
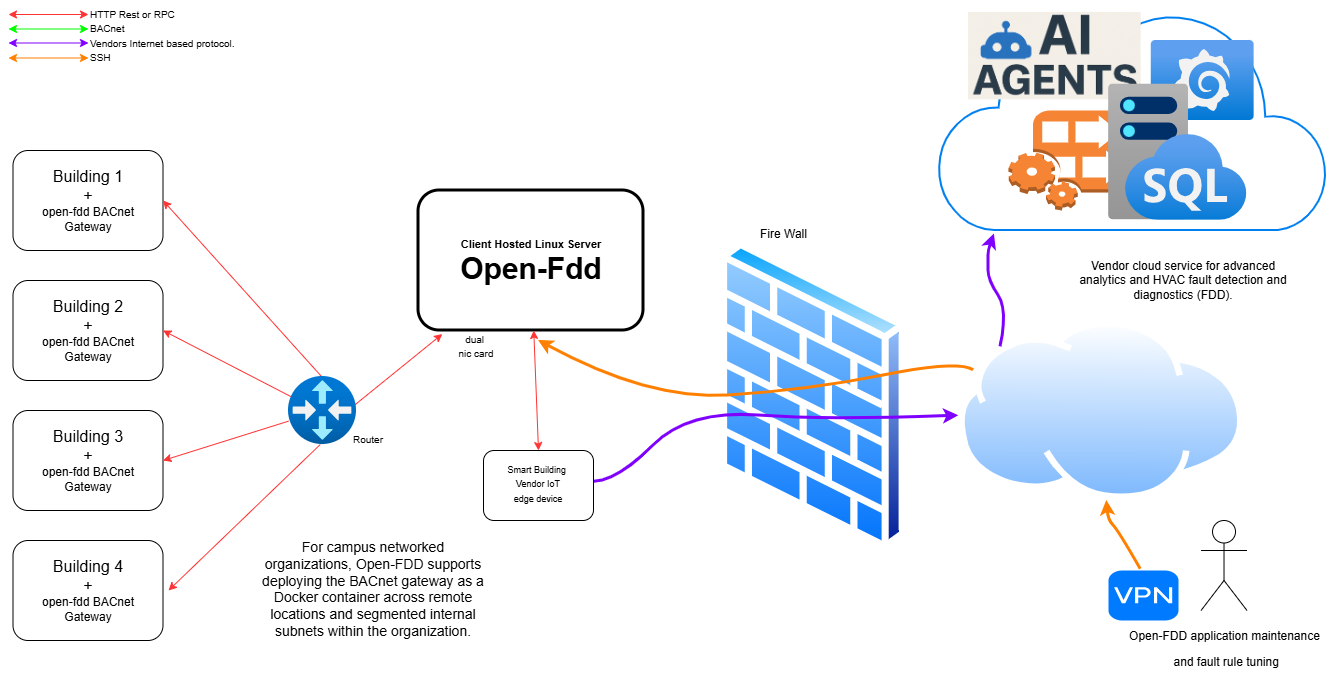
Remote Open-FDD BACnet gateways (e.g. diy-bacnet-server plus scraper) can be deployed across each subnet on the internal campus IT network. Typically each building has its own BACnet network on a unique subnet; a gateway per building or per subnet keeps BACnet traffic local while forwarding data to a centralized Open-FDD instance (API, Grafana, FDD loop, database). That gives the campus a single integration point for the cloud-based vendor of choice—one API and one data model for the whole portfolio, without the vendor touching each building’s BACnet network directly.
How to set it up: (1) Remote gateway per building (recommended pattern): On each subnet run diy-bacnet-server + scraper pointed at the central Open-FDD API—create each building’s site on the central API first and set OFDD_BACNET_SITE_ID (and related env) so readings and metadata align with the central data model. Prefer API-mediated configuration and ingestion over giving every gateway direct database credentials. (2) Central aggregator: On the central host run DB, API, Grafana, FDD loop (no local BACnet); set OFDD_BACNET_GATEWAYS to a JSON array of {url, site_id} so one scraper polls remote gateways (see Configuration — BACnet). (3) Advanced / internal-network only: Pointing OFDD_DB_DSN at the central Postgres from remote scrapers avoids the API path but widens exposure of the database—use only on a trusted LAN with locked-down firewall and ops approval; not the default recommendation. run_bacnet_scrape.py and per-gateway CSV/env options remain available for special deployments; they are not the default product path.
Data flow
- Ingestion: BACnet scraper and weather scraper write to
timeseries_readings(point_id, ts, value). - Data model (unified graph): The building is represented as a unified graph—one semantic model combining Brick (sites, equipment, points from the DB), BACnet RDF (from point discovery via diy-bacnet-server), platform config, and room for future ontologies (e.g. ASHRAE 223P). CRUD and POST /bacnet/point_discovery_to_graph update this model; SPARQL queries it. One TTL file
config/data_model.ttlholds the graph; a background thread serializes it to disk every 5 minutes (configurable viaOFDD_GRAPH_SYNC_INTERVAL_MIN); POST /data-model/serialize runs the same write on demand. - FDD (Python/pandas): The FDD loop pulls data into a pandas DataFrame, runs YAML rules, writes
fault_resultsto the database. Fault logic lives in the rule runner; the database is read/write storage. - Visualization: Grafana queries TimescaleDB for timeseries and fault results.
Ways to deploy
- Docker Compose (AFDD stack): In open-fdd-afdd-stack, run
./scripts/bootstrap.sh(see stack docs). - Minimal stack (BACnet-focused):
./scripts/bootstrap.sh --minimalin that repo — DB + BACnet server + scraper; no full API/FDD/weather unless you add services. - Engine only:
pip install open-fddand runRuleRunneron pandas DataFrames (no Compose); see Engine-only / IoT. - Manual / custom: Start your own processes; reuse the same rule YAML and
open_fdd.engineAPIs.
Key concepts
- Sites — Buildings or facilities.
- Equipment — Devices (AHUs, VAVs, heat pumps). Belong to a site.
- Points — Time-series references. Have
external_id(raw name),rule_input(FDD column ref), optionalbrick_type(Brick class). - Fault rules — YAML files (bounds, flatline, hunting, expression). Run against DataFrame; produce boolean fault flags. See Fault rules for HVAC.
- Unified graph — One semantic model (Brick + BACnet + platform config; future 223P or other ontologies). Stored in
config/data_model.ttl; maps Brick classes →external_idfor rule resolution; queryable via SPARQL.